OCR识别PDF乱码问题解决 |
您所在的位置:网站首页 › pdf ocr识别未知错误 › OCR识别PDF乱码问题解决 |
OCR识别PDF乱码问题解决
|
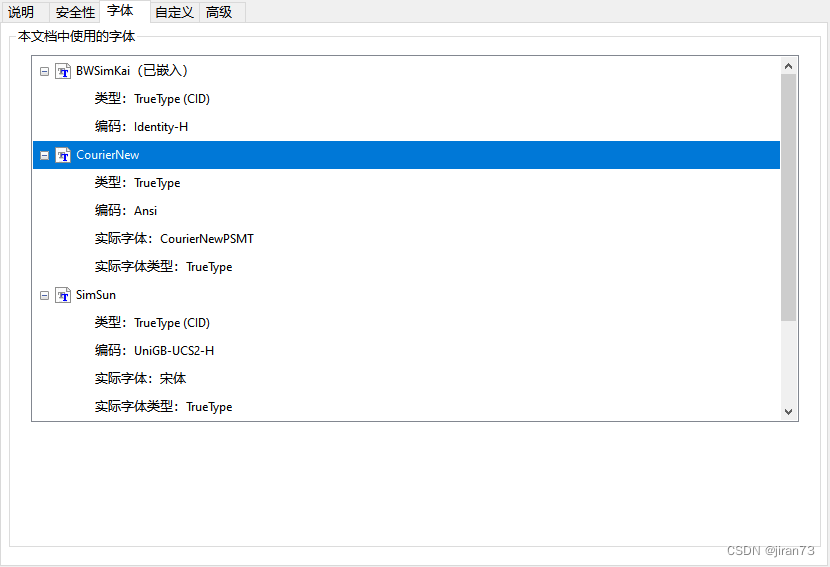
一、pdf转换后乱码的原因 pdf是一种可靠的文档传递格式,以Post语言文字模型为基础,不受操作系统和软件的影响,在每个设备上都能呈现出文件原始的面貌。 pdf文件本身并不具有文字编辑功能,目前pdf转换器都是以ocr文字识别技术为核心,将pdf转化为word、excel、ppt等格式,当pdf转换出现乱码时,首要原因便是转化器的ocr文字识别技术不到位,其次则是pdf中的字体属于罕见字体,导致转换器无法识别,要解决此类问题可以下载与pdf中相对应的字体,或更换pdf转换器。 二、pdf文档转换后出现乱码怎么办 1.首先在文档属性中检查该pdf文件所用的字体,将字体名称记录下来后将其关闭。
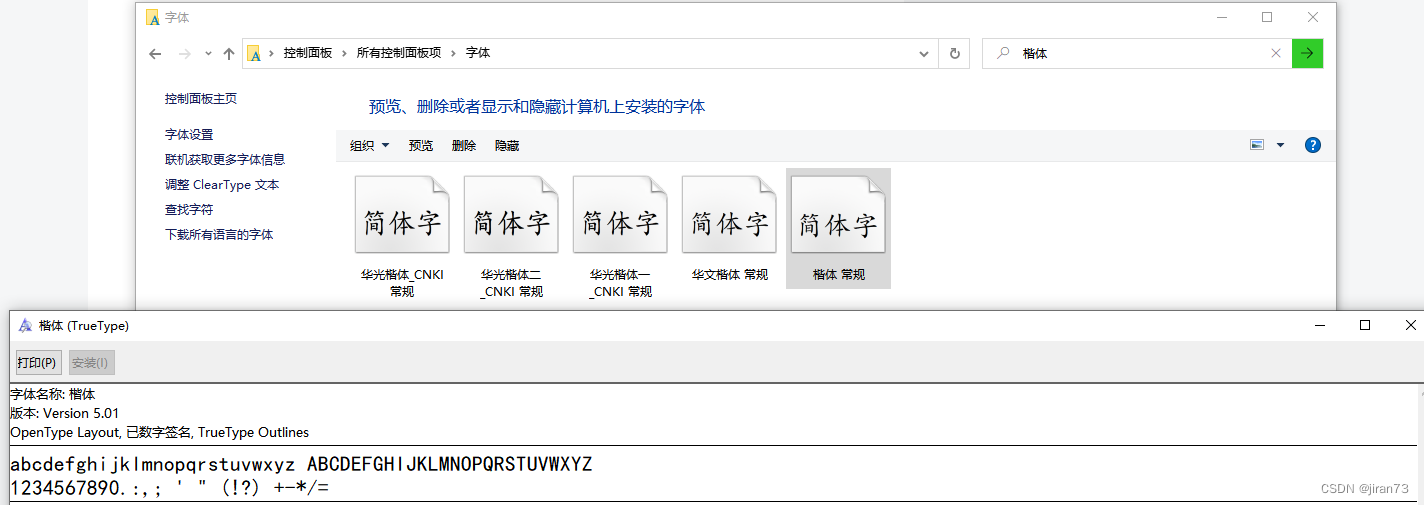
2.简要对比电脑自带,或者添加对应字体
3.确定符合,再对应环境的服务镜像中尝试添加该字体并验证 |
【本文地址】
今日新闻 |
推荐新闻 |